Lecture 4 Rendering on Game Engine
Intro
Rendering system in games
Is there any game without rendering?
有,MUD,文字游戏,通过控制台游玩
Rendering on Graphics Theory
- 图形学理论
- 实现的是拥有一种效果的各种物体
- 关注于图形表示和数学正确性
- 没有严格的表现性要求(无所谓丢帧)
- Realtime (30FPS) / interactive (10 FPS)
- 离线渲染
- out-of-core rendering
- 多机器离散渲染
- Realtime (30FPS) / interactive (10 FPS)
Challenges on game rendering
同时要处理拥有各种不同效果的大量对象
非常复杂
要跑在实际硬件基础上
需要理解现代计算机硬件架构
要保证稳定帧率
分辨率要求也越来越高
更短时间要绘制更高分辨率图像有限资源,需要为 CPU 留余地
GPU 可以有效利用,但 CPU 不能全被耗尽,需要用于支持 game logic 等
Rendering on game engine
不是理论模型,而是经过检验的工程模型
outline
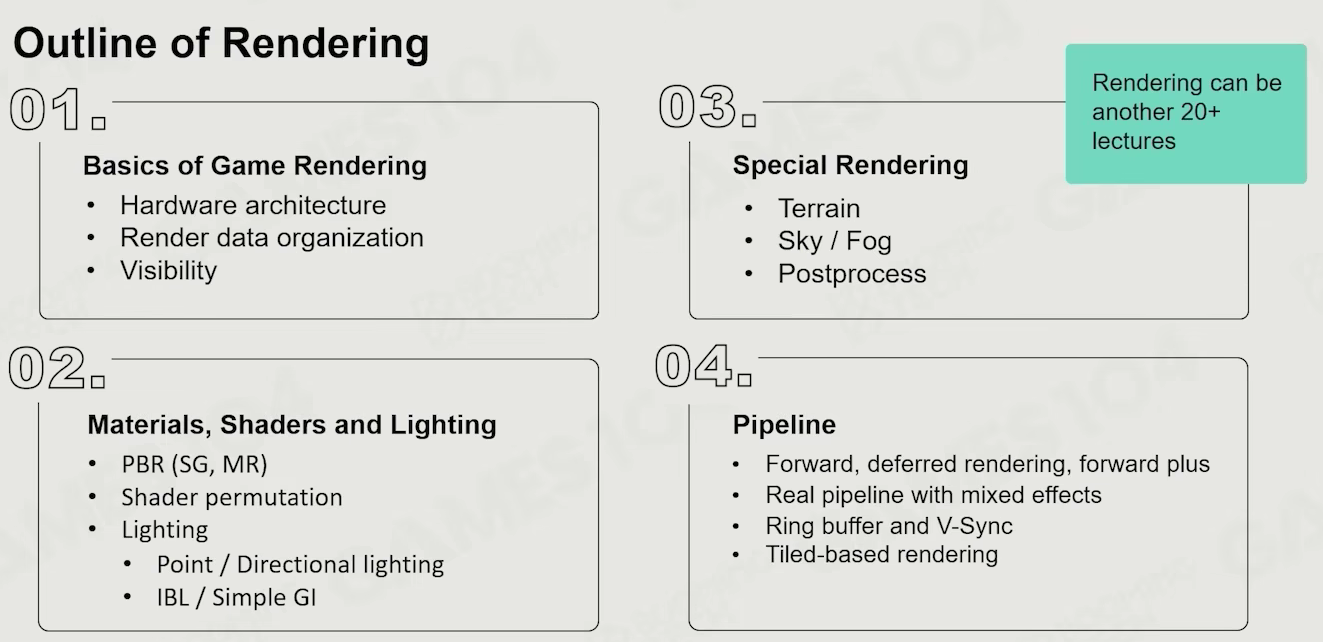
what is not included
- cartoon rendering
- 2d rendering engine
- subsurface
- hair/ fur

Building Blocks of Rendering
Rendering pipeline and data
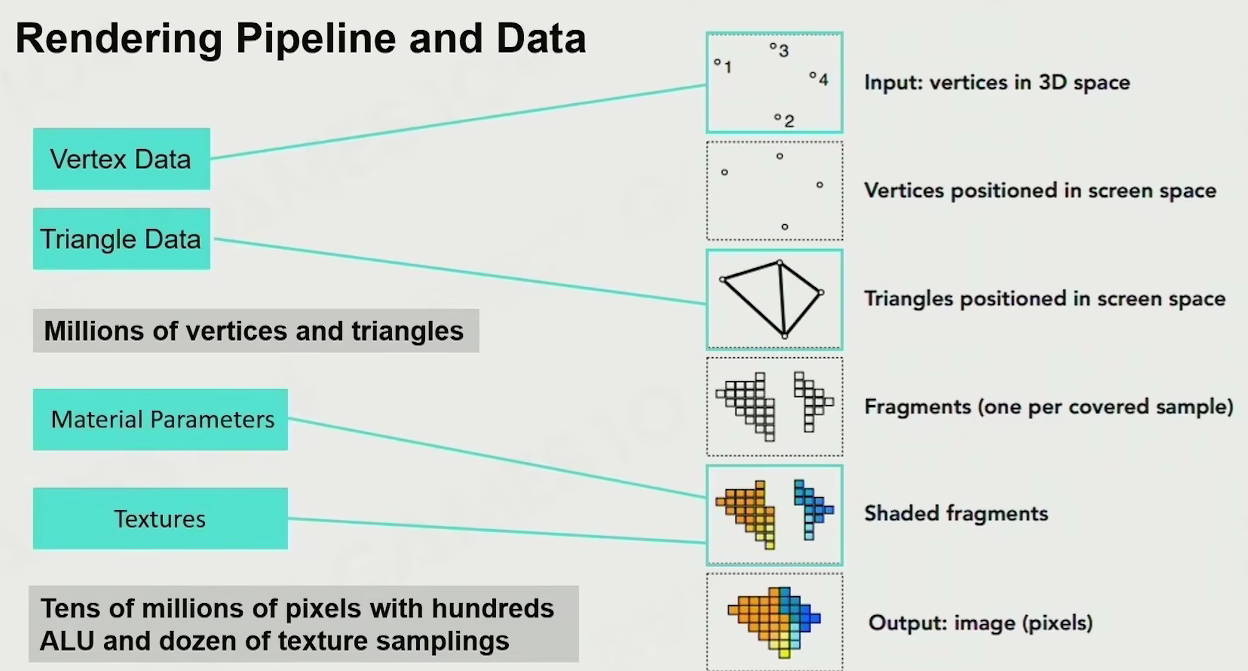
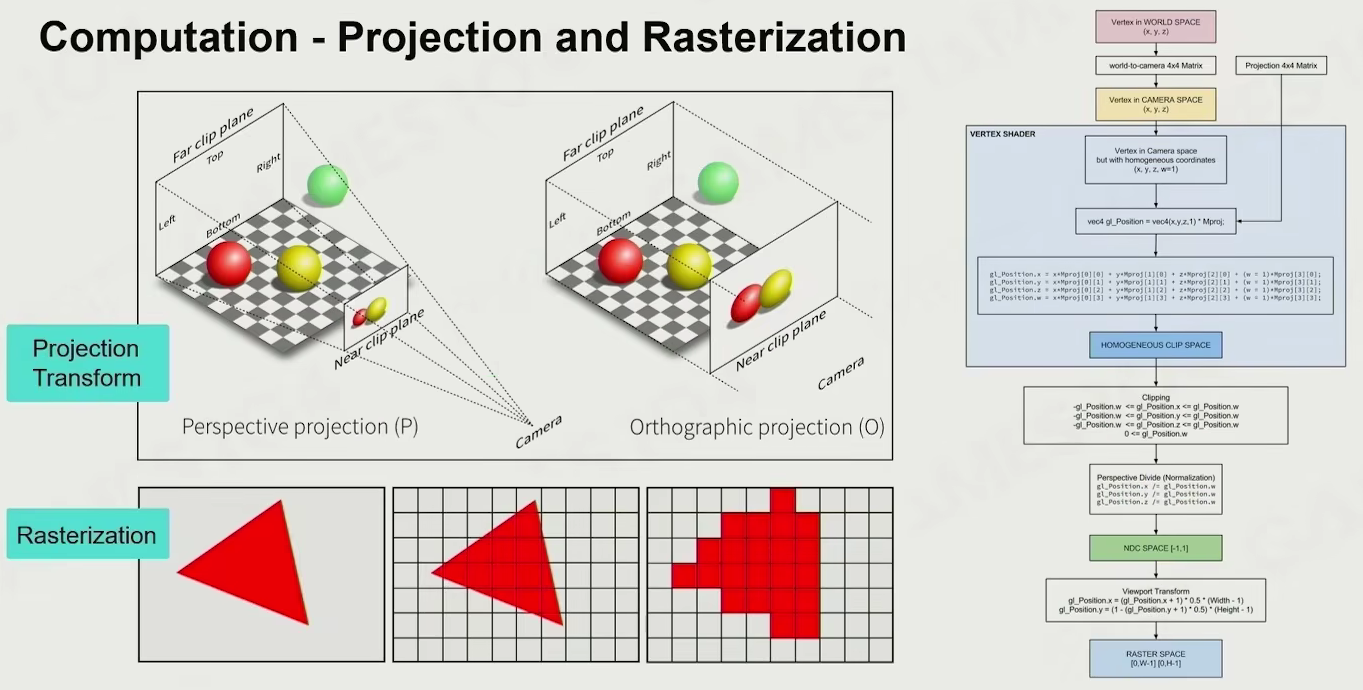
Computation - projection and rasterization
做的是躲在像素之后的事情
computation - shading
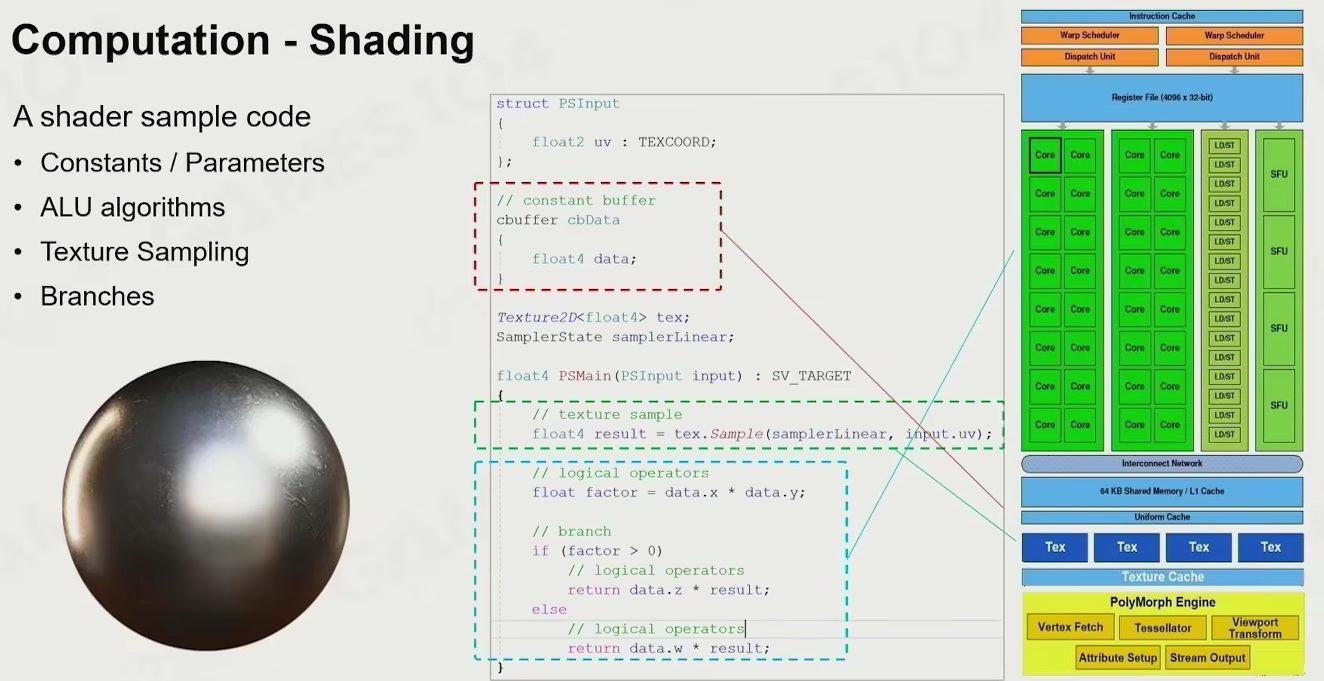
- 常量/参数访问
- 加减乘除
- 纹理采样
computation - texture sampling
离得近的时候,看得清楚
离得远的时候,中间其实隔了很多像素
由近及远的时候,其实画面就可能会抖动(走样)
每张贴图会存很多层,取点采样
八个采样点,七次差值
- 使用两个最相邻的 mipmap 层级
- 在两个 mipmaps 中进行双线性插值
- 在结果间进行线性插值
GPU
专门用于解决大规模运算的硬件
SIMD SIMT
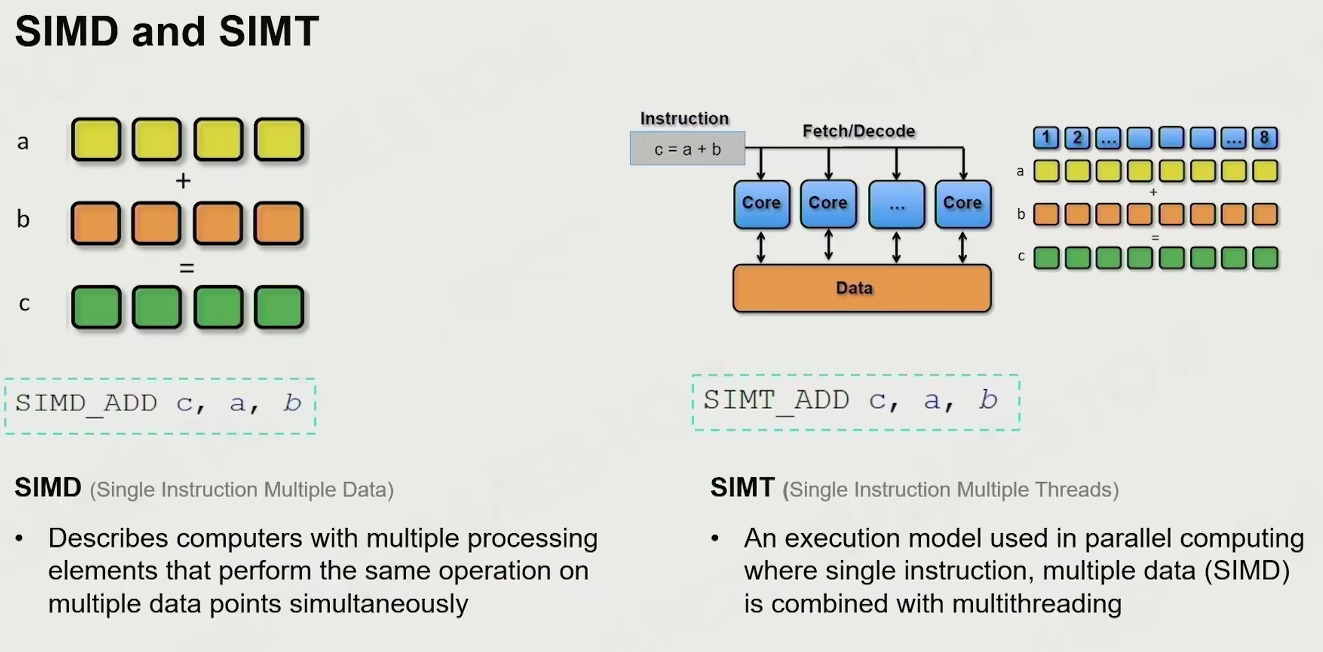
SIMD 单指令多数据
- 用多个运算原件同时在多个数据点处理相同运算
SIMT 单指令多线程
- 并行计算中所用的执行模型,在其中将 SIMD 与多线程结合
- 把单个计算内核做小,但做很多个
- 进行运算时可以在多个核上做同样指令
- GPU 算力比 CPU 快的原因:在做运算的时候尽可能用同样代码让大家一起跑 每个人(计算单元)分别访问自己的数据
GPU architecture
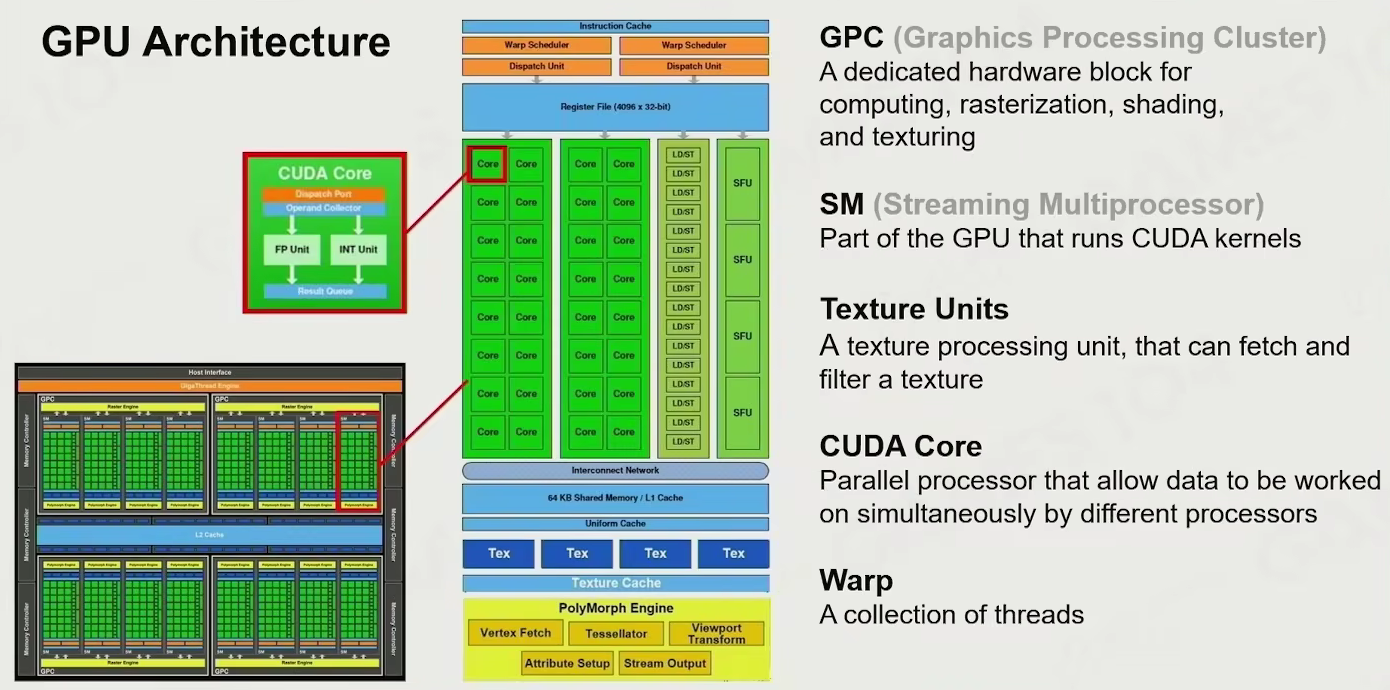
费米架构
一块显卡上放了很多内核,但分成一组一组(GPC,图形处理集群)
GPC 里面有很多 SM(流式多处理器),每个 SM 里面有很多 CUDA 核
CUDA 做大量数据运算
有专门的纹理单元
有很多专门的各种计算单元
不仅可以并行处理,也可以交换信息
Data flow from CPU to GPU
一开始是冯诺依曼架构,让计算与数据分开,但每个计算需要找数据,会产生大量开销
游戏引擎绘制引擎架构原则:尽可能让数据单向传输, CPU->显卡,不要从显卡里读数据
be aware of Cache Efficiency
- 要充分利用硬件并行计算
- 尝试避免冯诺依曼瓶颈
- 数据都在缓存上是最优的
- 老是 cache miss 速度就慢了
GPU bounds and performance
- Application performance is limited by:
- Memory Bounds
- ALU Bounds
- 数学计算太多 其他都做完了 但在等数学运算结果
- TMU (Texture Mapping Unit)
- Bound BW (Bandwidth) Bound
流水线:木桶的短板效应,会受限于最慢的那一环节
modern hardware pipeline
硬件结构其实不停在变
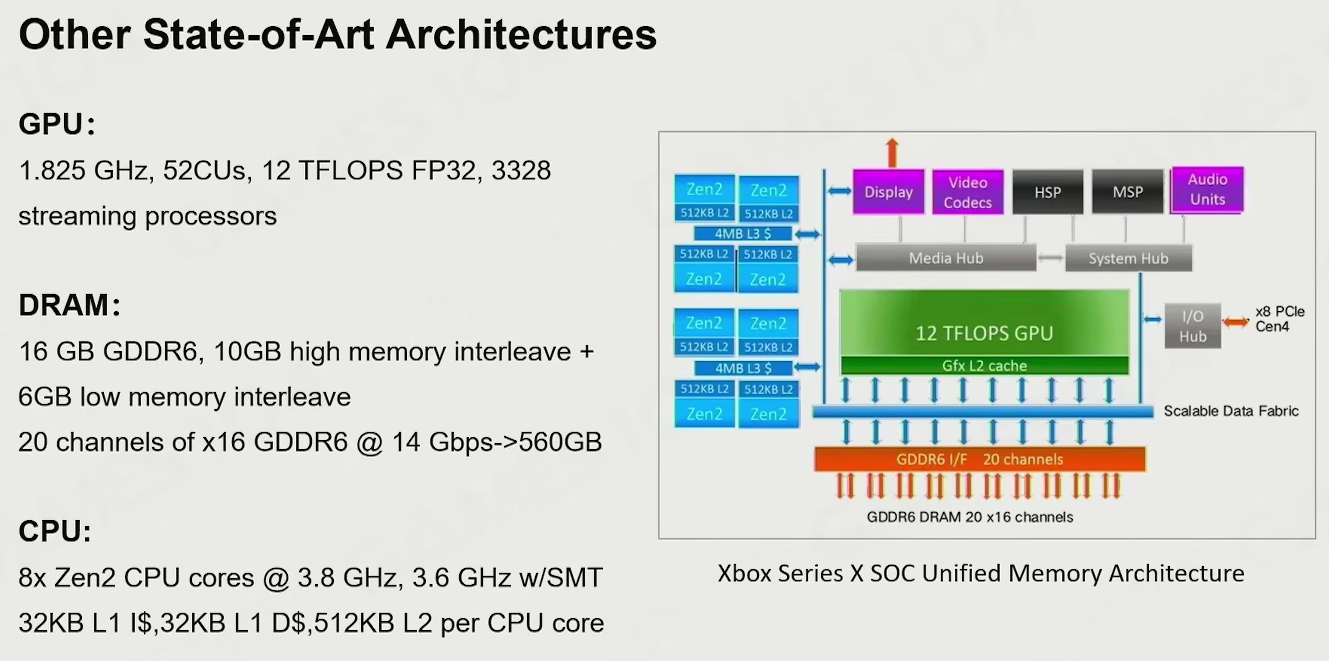
other state-of-art architectures
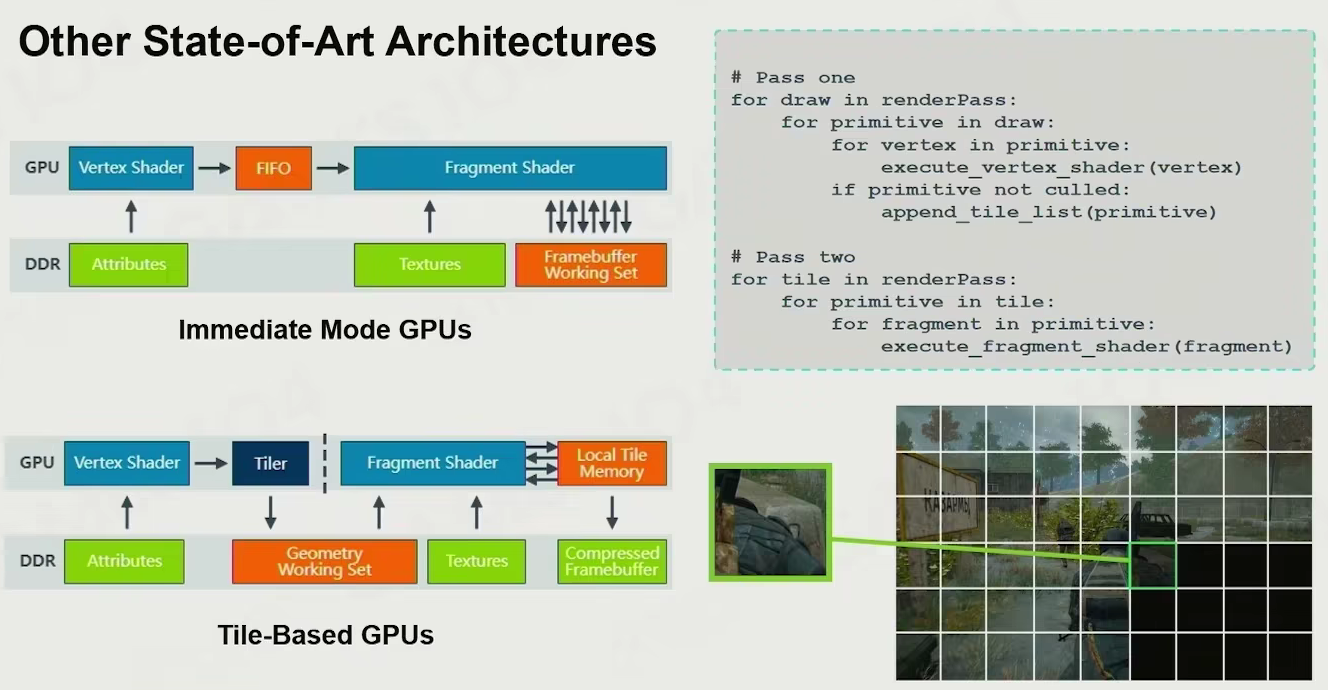
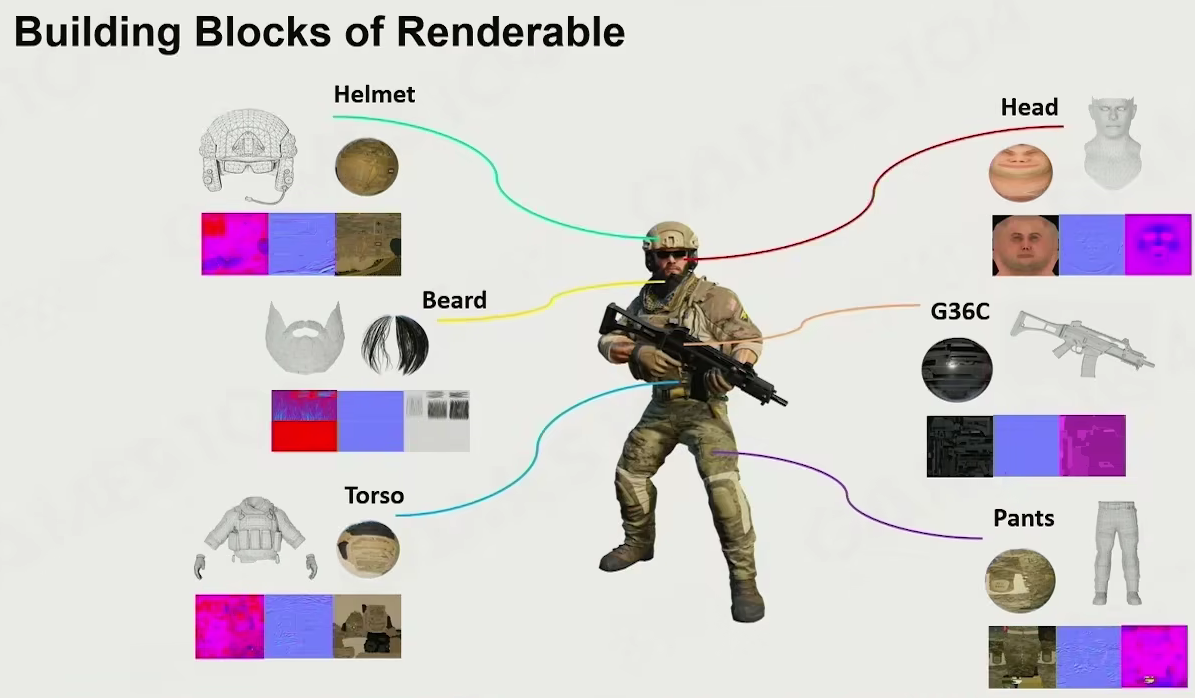
Renderable
Mesh Render Component

Building Blocks of Renderable
Mesh Primitive
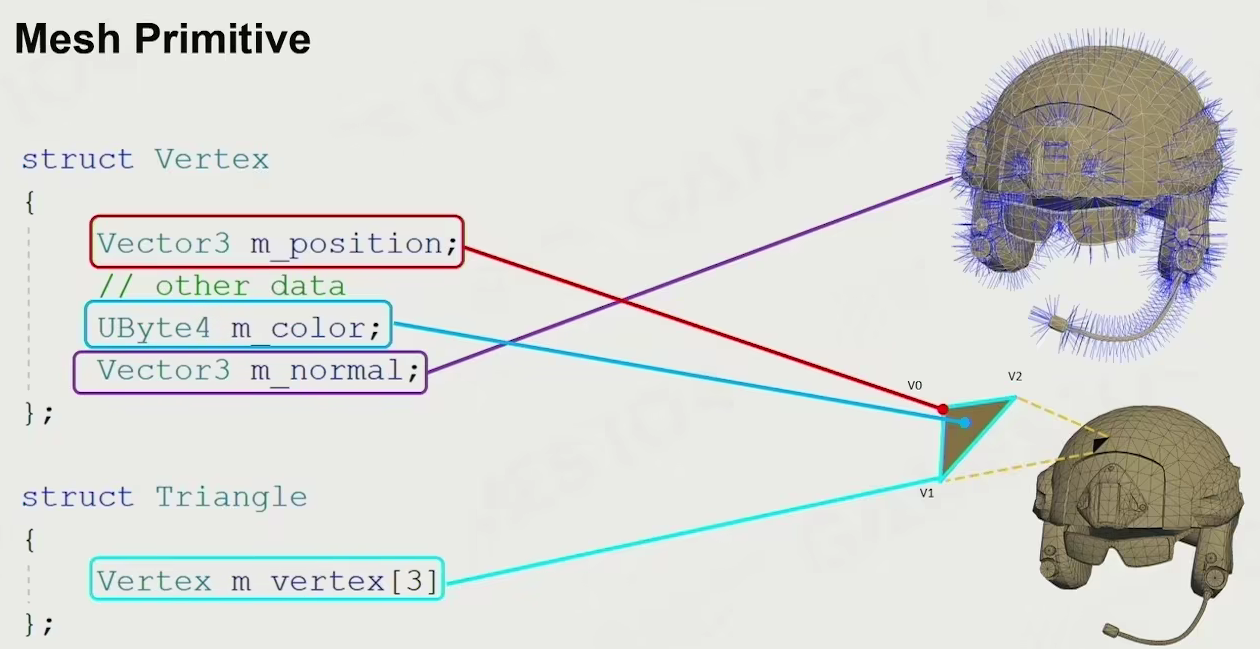
包含顶点数据,法向量数据,UV 等数据
Vertex and Index Buffer
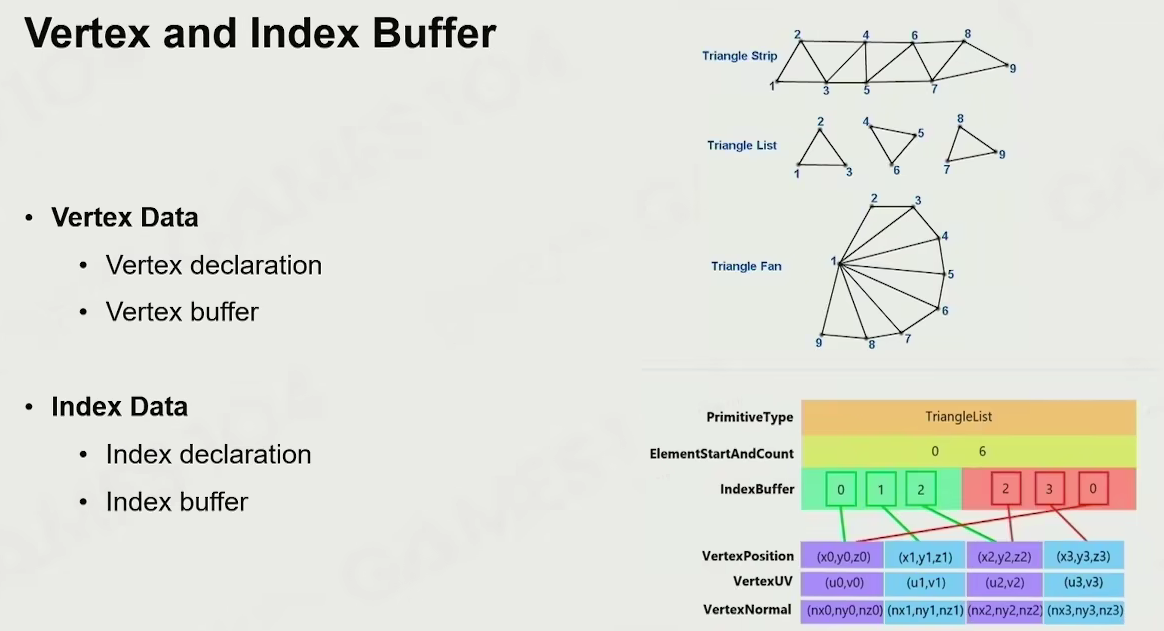
并不直接存储 vertex,转为存储 index,可以通过索引找到相应的 vertex 数据
因为有很多顶点是共用的
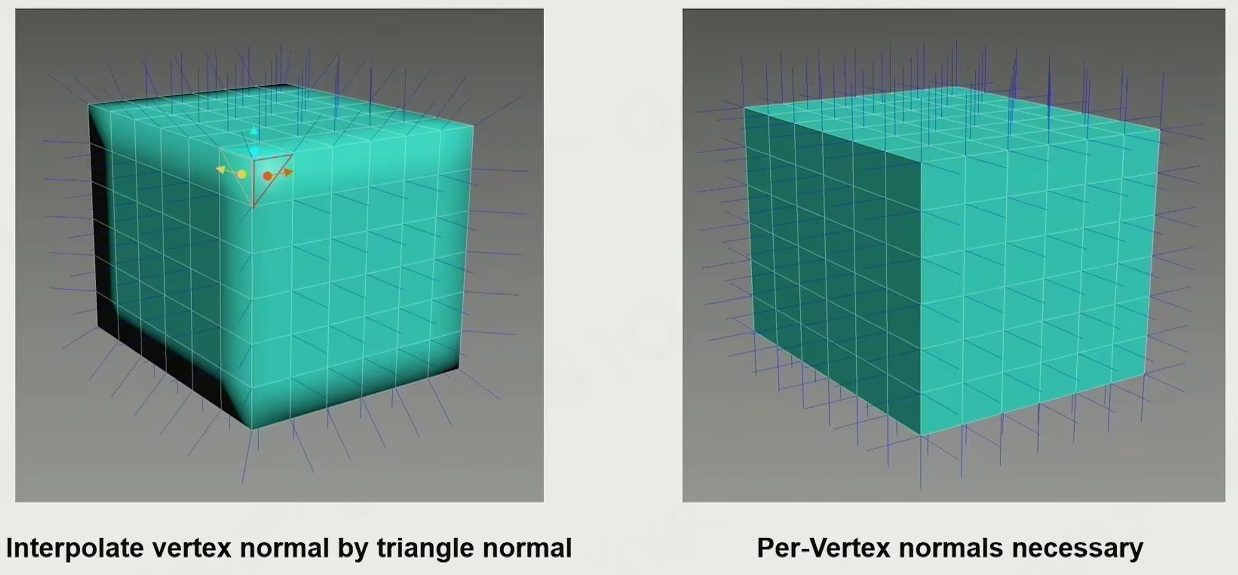
why we need per-vertex normal
为什么每个顶点要存一个法向量
一旦表面是硬表面(有折线),两个顶点即使重合,其法向完全不同
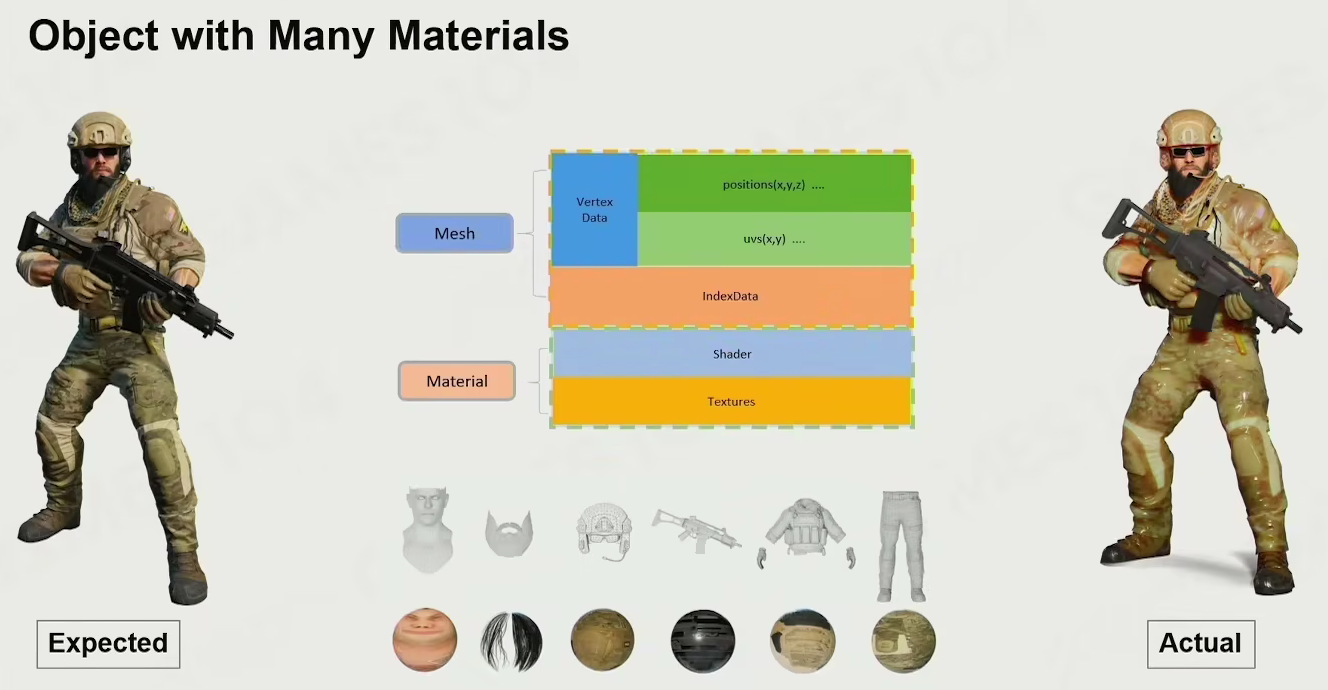
materials

材质决定物体看起来是什么样的
只决定视觉材质
后面还有 physics material
摩擦系数
弹力等
famous Material Models

Various Textures in Materials

很多时候看起来像什么是由纹理而不是材质决定的
variety of shaders

- 数据(assets)
- source code
- shader(被当做数据的 code)
Render Objects in Engine
Coordinate System and Transformation
类似照相机拍照:
- 固定相机在三脚架,并让其对准场景
从不同位置观察场景(视图变换) - 对场景进行安排,使各个物体在期望位置
移动,旋转,放大/缩小场景物体(模型变换) - 选择相机镜头,调整焦距
现实物体时,选择其投影方式(正交/透视) - 确定照片大小,放大还是缩小照片
绘制图形,是要占据整个屏幕还是屏幕的一部分(视口变换)
object with many materials
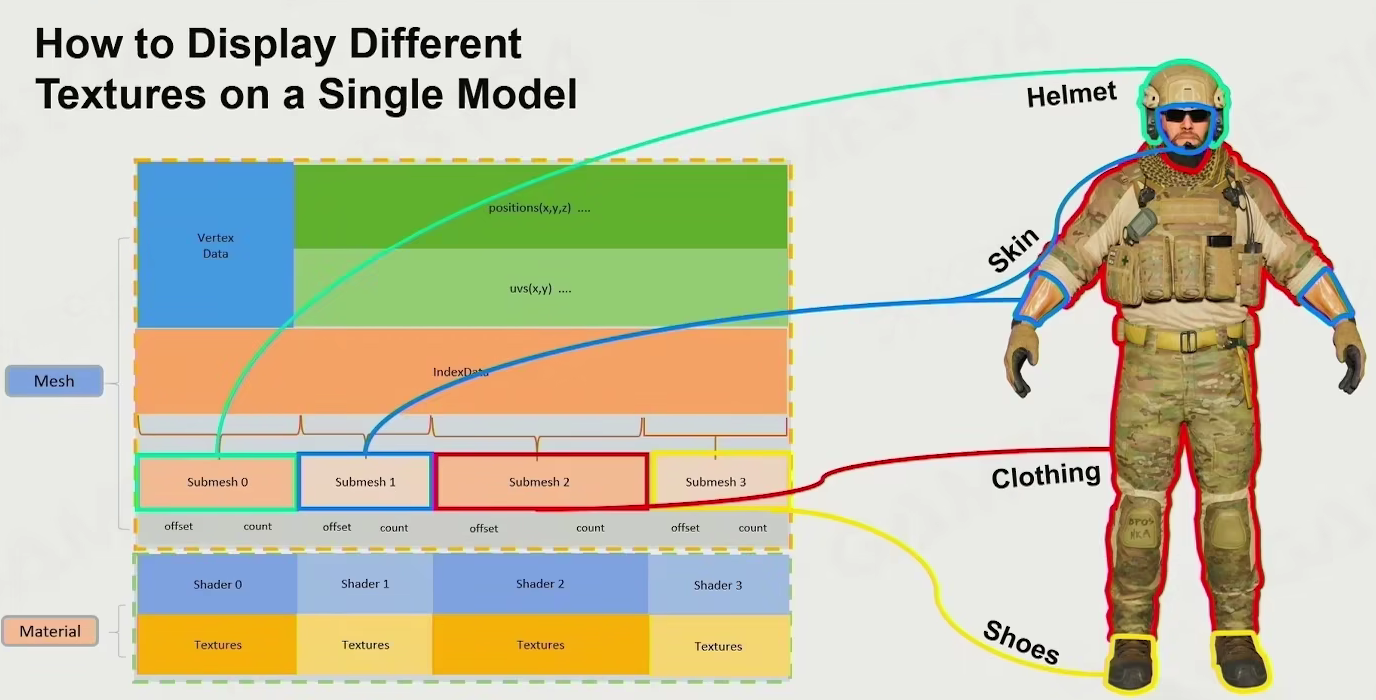
How to Display Different Textures on a Single Model - submesh
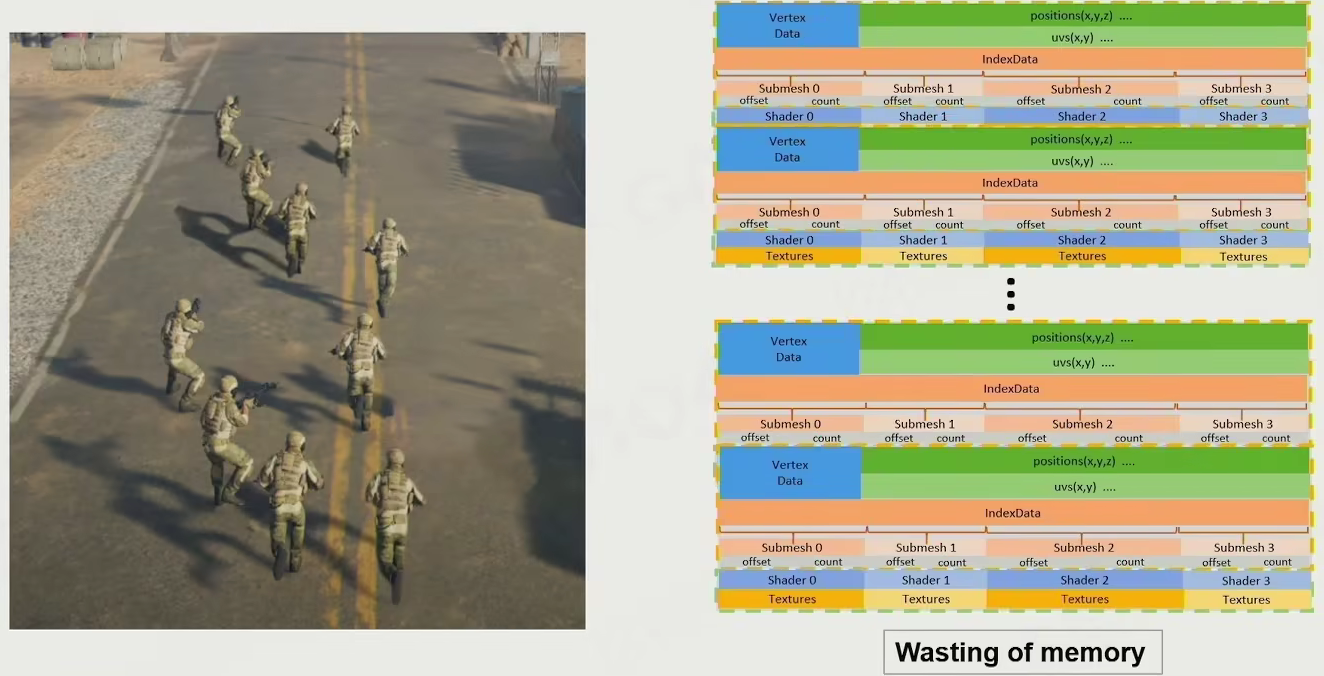
Resource Pool
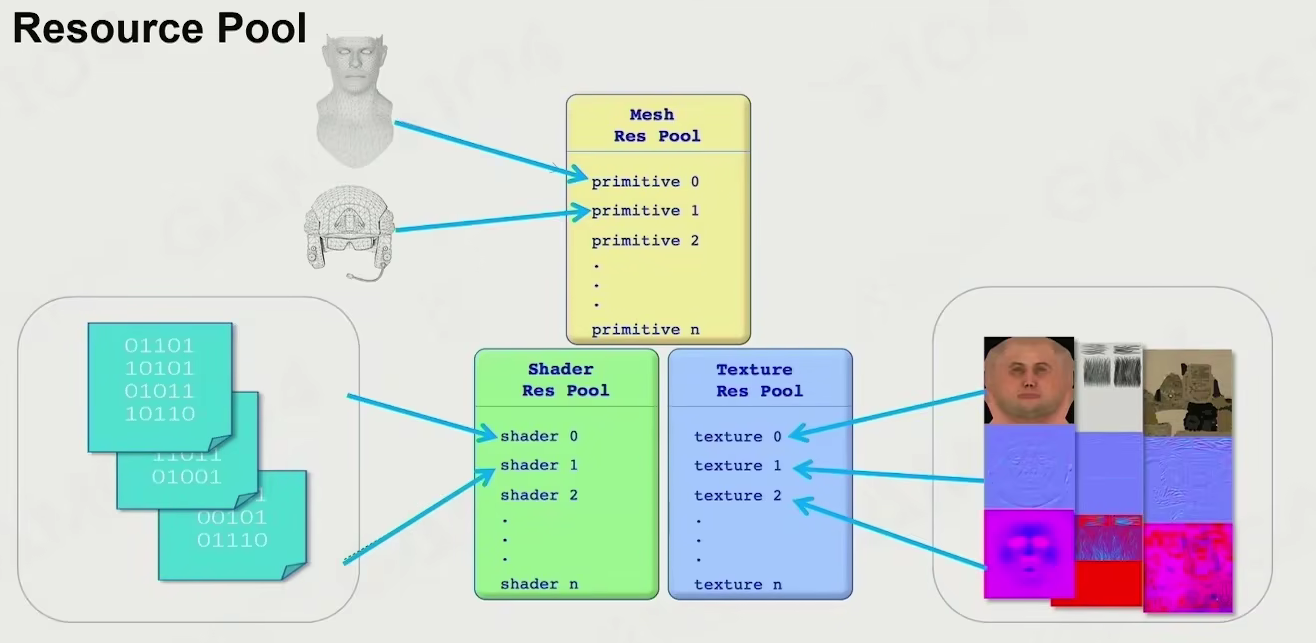
建立统一资源库
- mesh
- shader
- texture
instance: use handle to reuse resources
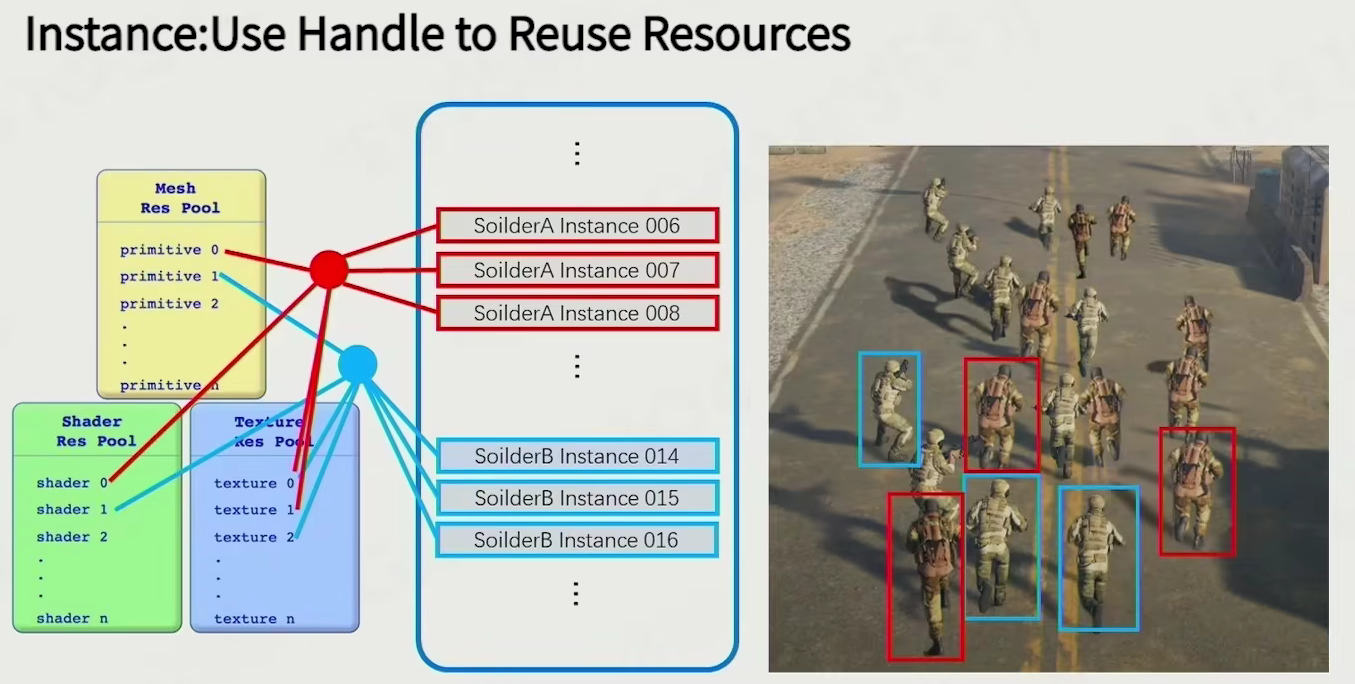
只需找到相应实例就可以复用相应数据
sort by material
GPU上的每一次数据交换都会导致效率下降
场景中的物体按照材质排序,相同材质放一起,显卡处理效率会提高
GPU Batch Rendering
很多物体其实是一致的,一次绘制指令为同样的物体统一绘制(如大量的树木、草等)
Visibility Culling
事件锥 - 只有所见范围内的东西才有意义
看不见的东西可以不绘制
culling one object
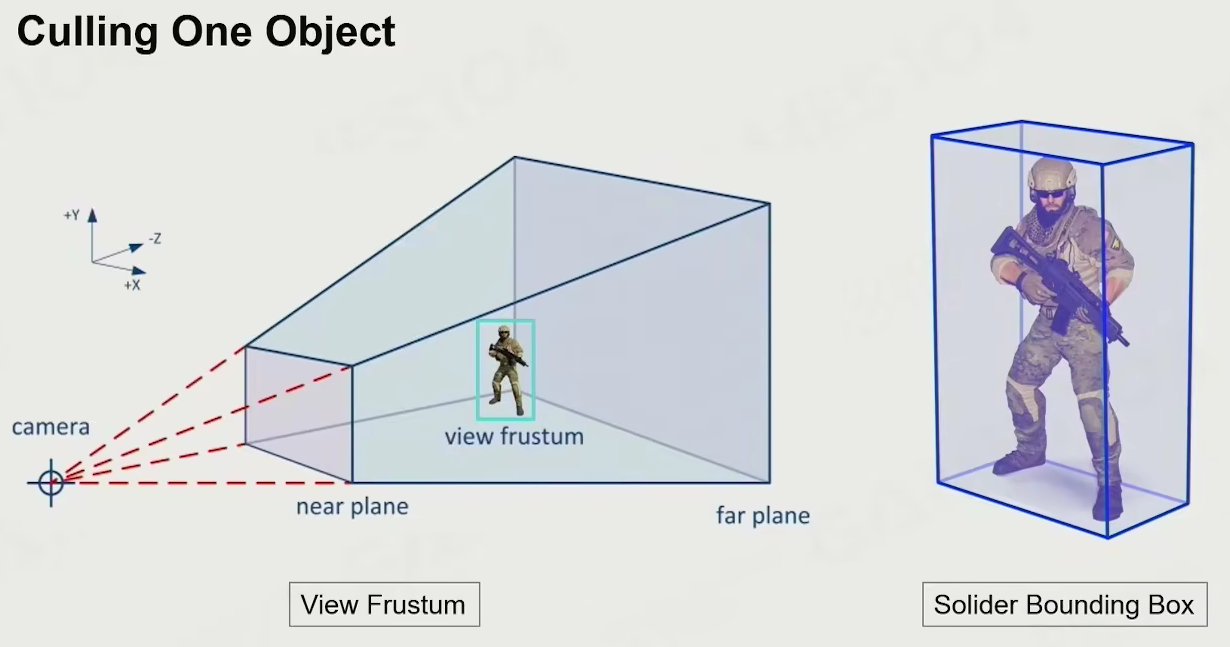
看物体包围盒是否在事件锥中
using the simplest bound to create culling
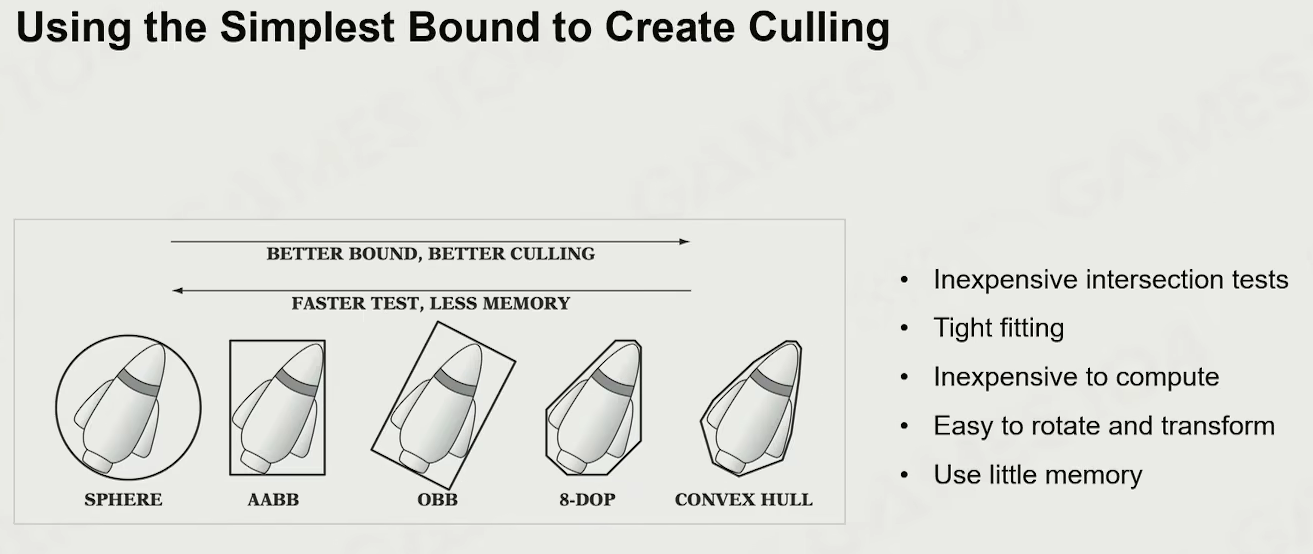
- SPHERE
- AABB
- 存两个端点
- OBB
hierarchical view frustum culling
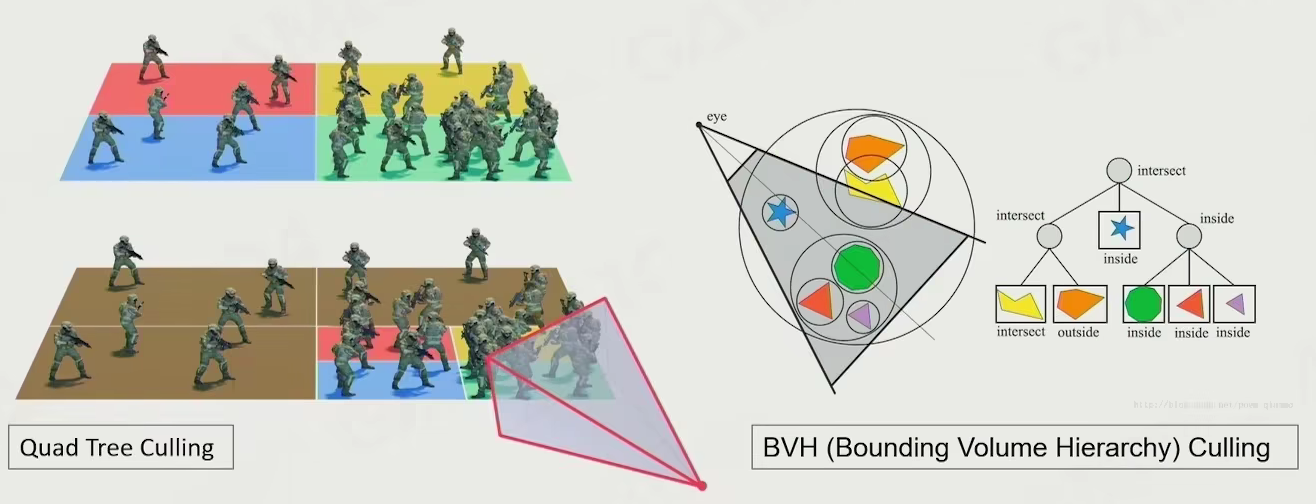
层级询问,如果最大的包围盒看不见,直接不渲染,依次向下询问
construction and insertion of BVH in game engine
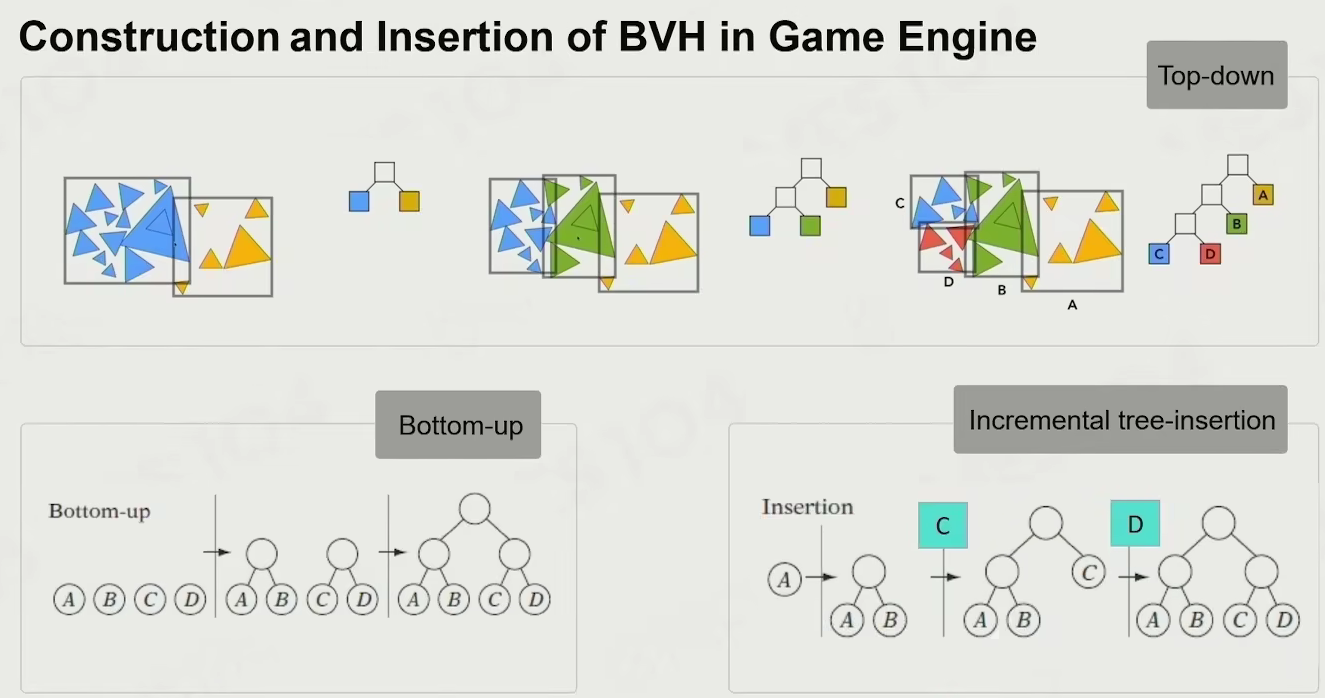
现代游戏引擎中 BVH 用得多:
- 很多东西在动,对于已经建立好的树,重建树状结构会相对快
PVS
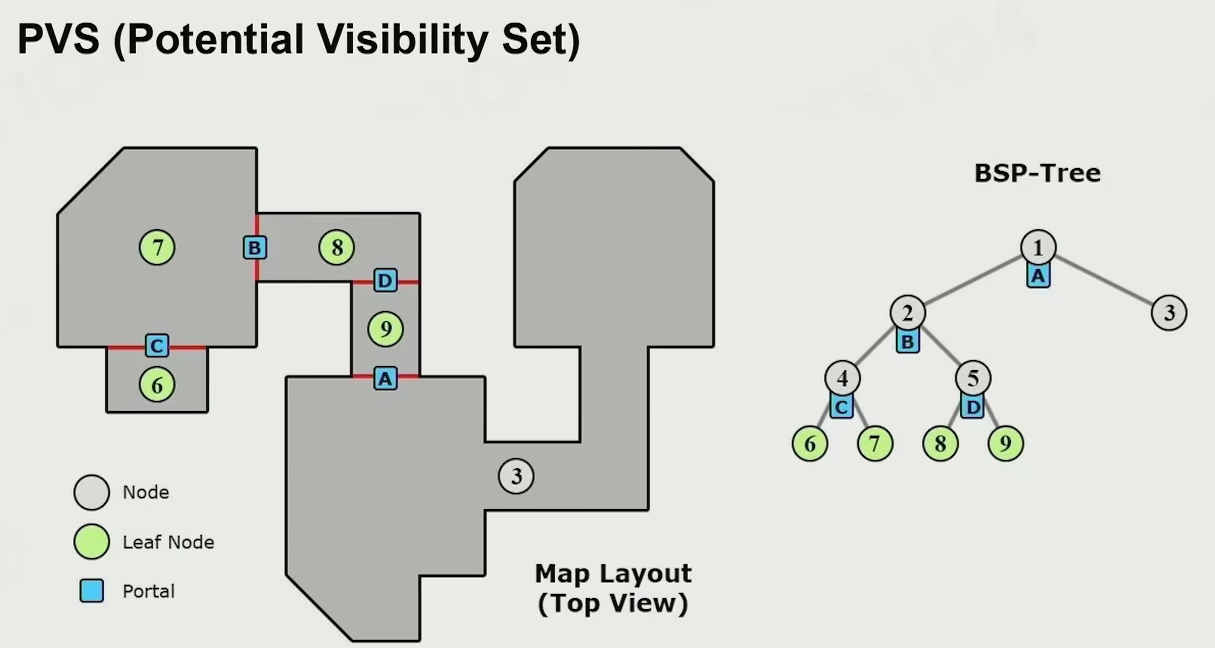
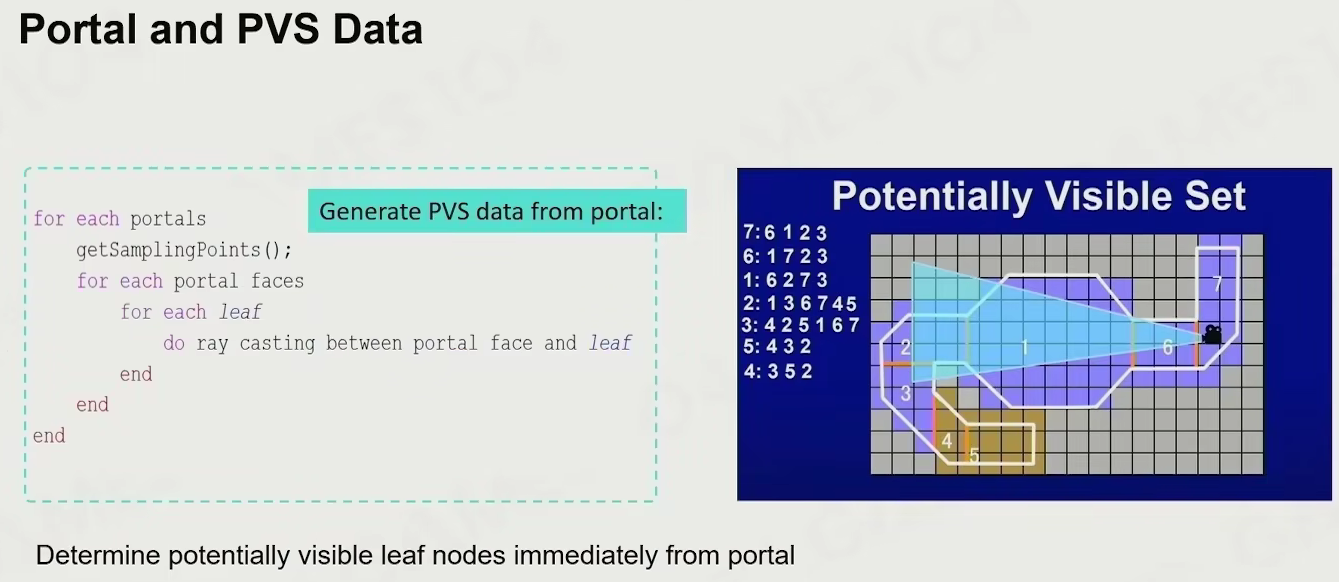
- 先把空间分割
- 每个空间用 portal 连接
- 通过 portal 能看到的范围是固定的
- 只渲染可见范围内的物体
the idea of using PVS in stand-alone games

虽然现代游戏 全用 PVS 的较少了,但思想很有用
游戏玩家所经过的区域为 zone,每个 zone 内的可见范围有限,这可以帮助资源的动态加载
GPU Culling
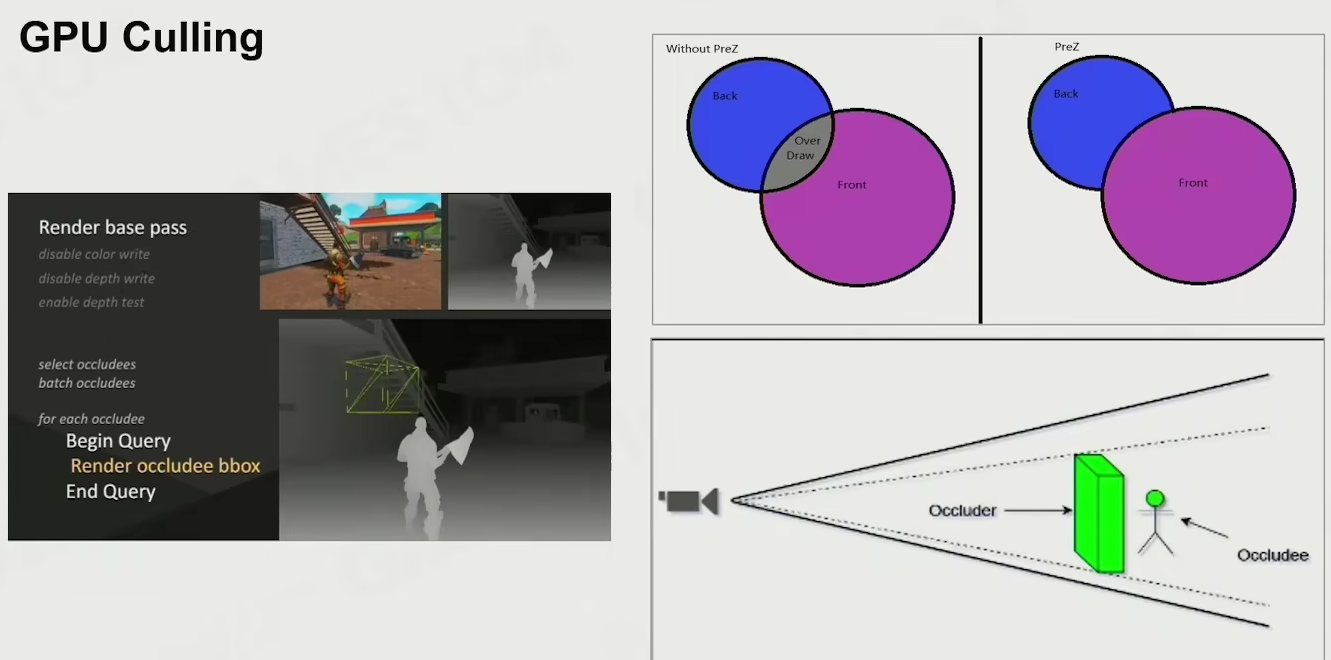
现在可能更多用显卡算力来直接解决
现有的一种解决办法:先绘制场景深度,被挡住的就不绘制
Texture Compression
纹理压缩
渲染的基础是 renderable 其中重要的 component 是纹理,在游戏引擎中会将纹理压缩
- 传统图像压缩(JPG/PNG)
- 很好的压缩率
- 高图像质量
- 专门用于压缩/解压一整张图片
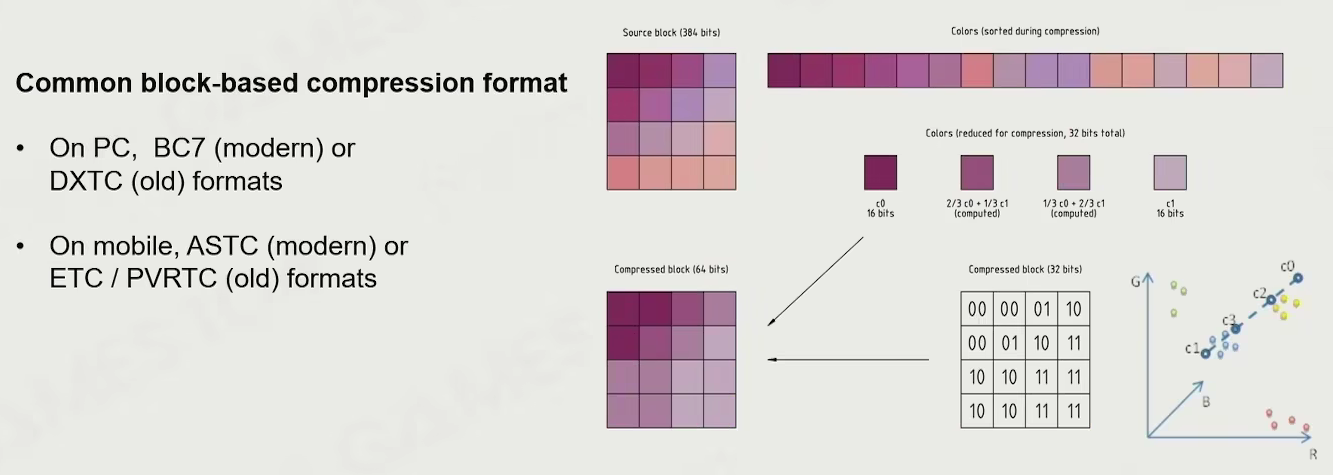
- 游戏纹理压缩 - block-based
- 解码速度快
- 可随机访问
- 保证压缩率和可见质量
- 编码速度快
block compression
先找颜色最亮和最暗的点,将其他点视为最大最小的插值,存储一个点和最大最小点的远近关系
主要用于 PC
手机上用的算法不一定再是 4 x 4,可能不能在运行中压缩
Authoring Tools of Modeling
Modeling
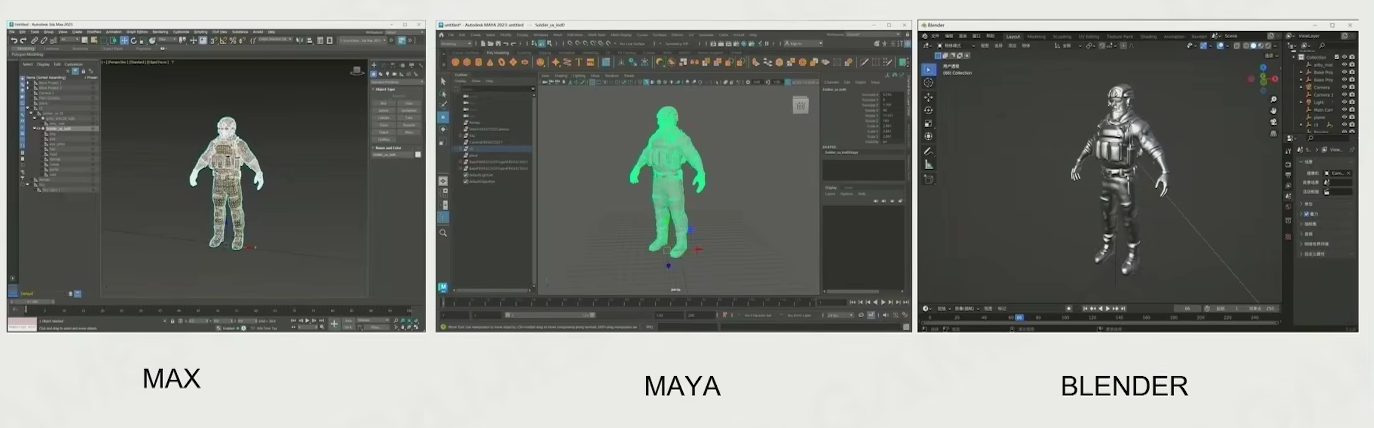

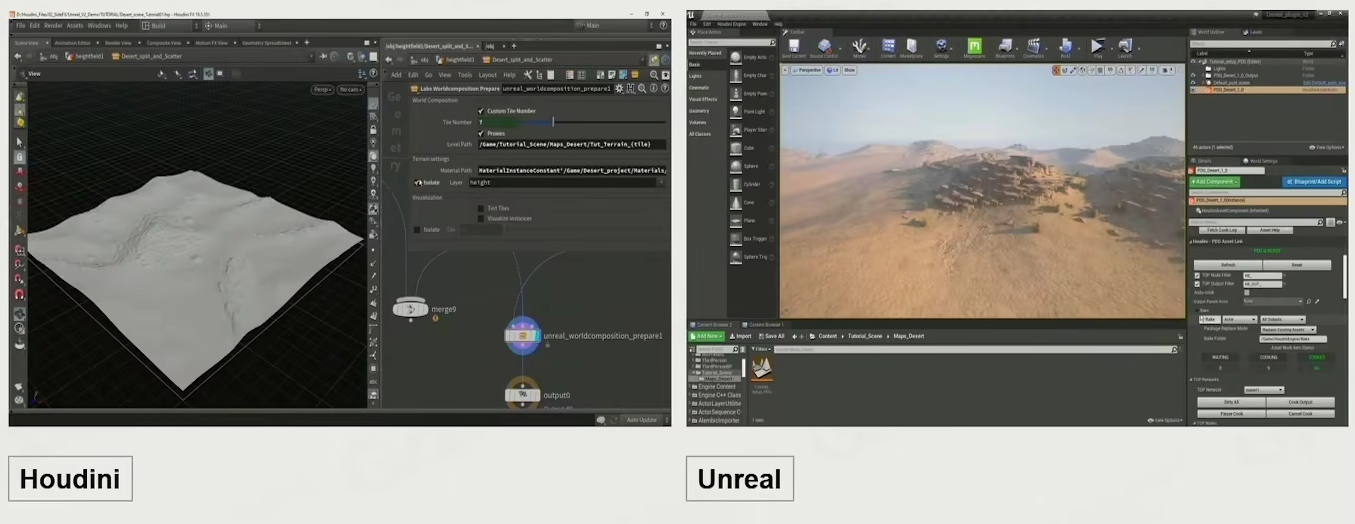
Comparison of Authoring Methods

Cluster-Based Mesh Pipeline
Sculpting Tools Create Infinite Details
- 艺术家创建的模型拥有的细节越来越多
- 线性 FPS 发展到 开放世界 FPS,每帧提交的复杂场景数据几乎提升十倍以上
Cluster-Based Mesh Pipeline

15 年育碧做刺客信条大革命的时候提出
当面对精细模型,将其分为小的 cluster(固定的 32/64 单元)
很多东西其实是一样的,丢给硬件自己画
programmable mesh pipeline
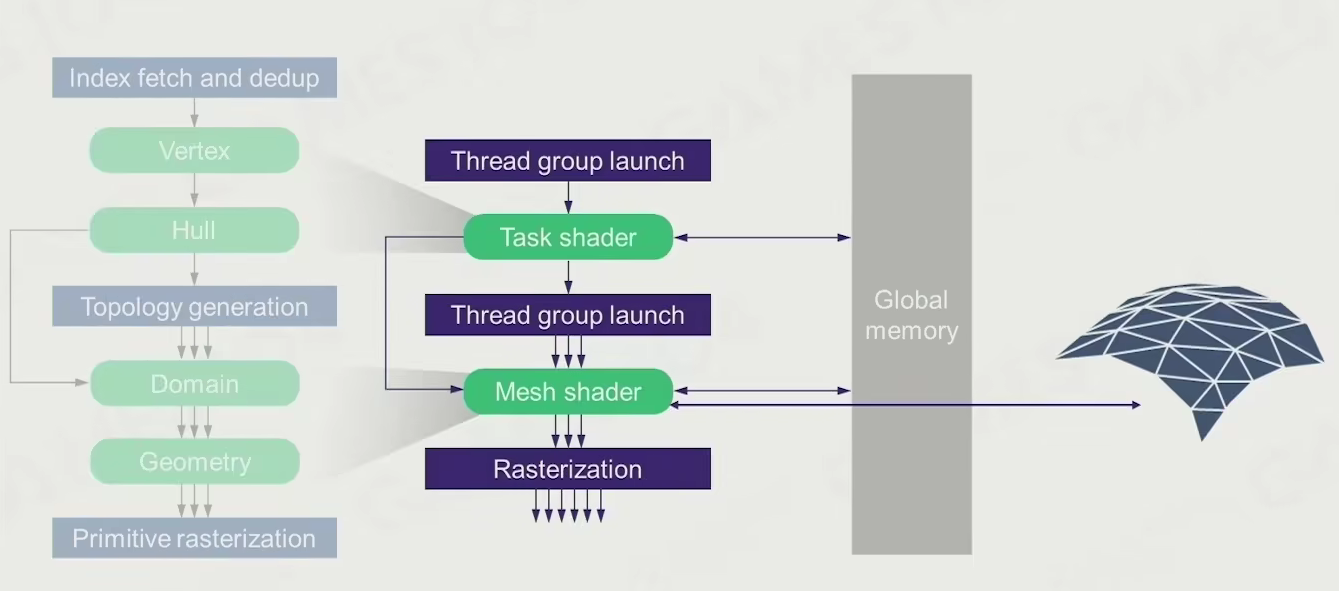
可以用一个算法,基于数据,凭空生成,并且可以根据远近自动选择合适的
好处:可以产生无限细节
GPU Culling in Cluster-Based Mesh
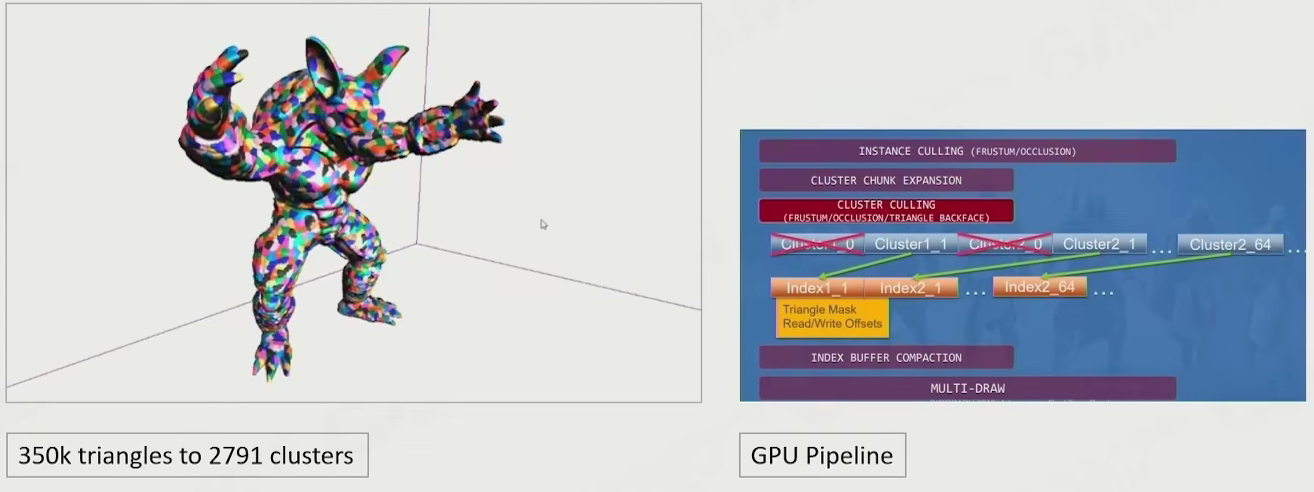
现在的裁剪可以部分裁剪
Nanite

Take Away
- 游戏引擎的设计是工程科学,依赖于对现代图形硬件(显卡架构)的理解
- 核心要解决的 Mesh、模型、材质等数据间关系
- 尽可能通过运算来减少绘制需求(可见性很重要,看不见的就不绘制),优化的最高境界就是 do nothing
- GPU 越来越强,很多需要在 CPU 做的复杂运算都交给了 GPU:GPU-Driven
go through code
build/Pilot.sln
Mac 下是
Pilot.xcodeproj
核心是 PilotRuntime 文件PilotPreCompile 是自动生成的
- 在哪里找资产
../Engine/asset/level/1-1_level.json
- 引擎如何读数据?
- 找到
PilotRuntime/resource/res_type/common/level.h- 里面包含
REFLECTION_TYPE - 包括看到
ObjectInstanceRes的定义也是带反射类型的REFLECTION_TYPE - 里面的每一个变量名都会变成 json 里的一个描述文件
- 里面包含
- 找到

原来这里才是正式要求第一次作业的地方哈哈,还有课程官网,我就说嘛不然啥也没说,直接纯摸估计要费不少时间,还是有指导文档的嘿嘿,好评!
老师们辛苦了,致敬。
Q&A
- 引擎中还有其他 instance 的案例吗
- 每个 GO 其实都是 instance
- 音乐/音效也是
- mesh shader/ clustered mesh 未来会怎么发展
- 会是未来发展方向
- 硬件会越来越复杂 越来越高效
- 让每个单元处理简单运算的思想是未来的趋势
- 引擎有必要自写渲染管线吗
- 很多引擎会写
- 渲染是工业化问题 一定时间后其实发展会趋同
- 多学习同行中的主流方案构建方法
- 图形代码有没有更好 debug 方法
- 很难
- 很多计算在 GPU 中,只能看到结果,但不一定知道中间哪里出了问题
- 要小步迭代反复验证,不要一次写太多,不然不知道问题出在哪里



